Understanding Key Parameters for Tuning LLM Outputs
Tuning outputs from Large Language Models (LLMs) involves a complex decoding process that shapes the model’s next-token distribution. By adjusting a set of sampling controls, users can significantly influence the quality and relevance of the generated text.
Key Parameters for LLM Tuning
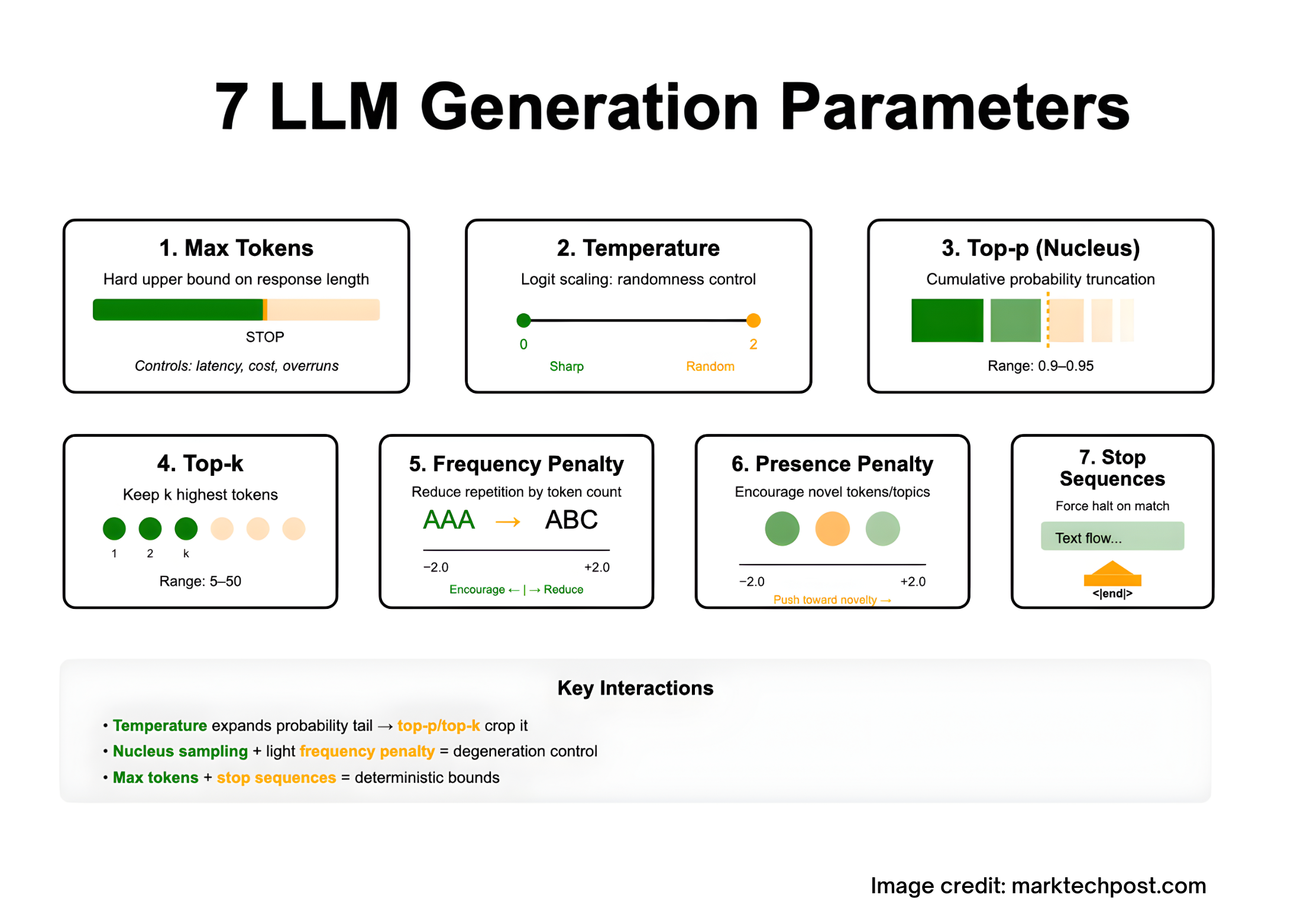
Here are seven critical parameters that play a vital role in generating optimal outputs:
- Max Tokens: This parameter sets a hard upper limit on the number of tokens the model can generate, ensuring responses remain concise and within the model's context window.
- Temperature: This scalar affects the randomness of predictions. A higher temperature increases variability, while a lower temperature results in more deterministic outputs.
- Top-p (Nucleus Sampling): This method truncates the candidate set based on cumulative probability mass, allowing for more diverse outputs while maintaining quality.
- Top-k: Similar to top-p, this parameter limits the candidate tokens to the top k most probable options, balancing randomness and coherence.
- Frequency Penalty: This parameter discourages the model from repeating the same phrases, promoting more novel content in longer outputs.
- Presence Penalty: Used to encourage the inclusion of new topics within the generated responses, helping to avoid redundancy.
- Stop Sequences: These are defined delimiters that signal the model to terminate generation, providing a structured endpoint for outputs.
Each of these parameters interacts with one another. For example, the temperature setting can widen the candidate space that top-p and top-k will subsequently crop. Additionally, penalties can help mitigate degeneration during extensive text generation, while combining stop sequences with max tokens can ensure outputs remain within defined limits.
Conclusion
As AI technologies continue to evolve, understanding these parameters becomes essential for professionals aiming to leverage LLMs effectively. The insights provided by Michal Sutter in MarkTechPost serve as a valuable guide for those looking to fine-tune these models to meet specific needs and enhance overall output quality.
Rocket Commentary
The article emphasizes the intricate mechanics of tuning Large Language Models (LLMs), showcasing the nuanced balance of parameters like temperature and top-p sampling in shaping output quality. While this technical focus is essential for developers aiming to optimize AI, it underscores a broader concern: the accessibility of these tools for non-experts. As AI technology becomes increasingly sophisticated, ensuring that businesses, regardless of size or technical expertise, can leverage these capabilities ethically and effectively is crucial. If LLMs can be fine-tuned to produce more relevant and concise outputs, the potential for transformative applications in various industries is significant. However, the onus lies on developers and organizations to democratize this knowledge, fostering an environment where AI can drive innovation while remaining grounded in ethical principles.
Read the Original Article
This summary was created from the original article. Click below to read the full story from the source.
Read Original Article