Introducing VLM2Vec-V2: A Breakthrough in Multimodal Embedding Learning
A significant advancement in the realm of artificial intelligence has emerged with the introduction of VLM2Vec-V2, a unified computer vision framework designed for multimodal embedding learning. This framework encodes diverse multimodal information into a shared dense representation space, effectively bridging the gap between various data modalities.
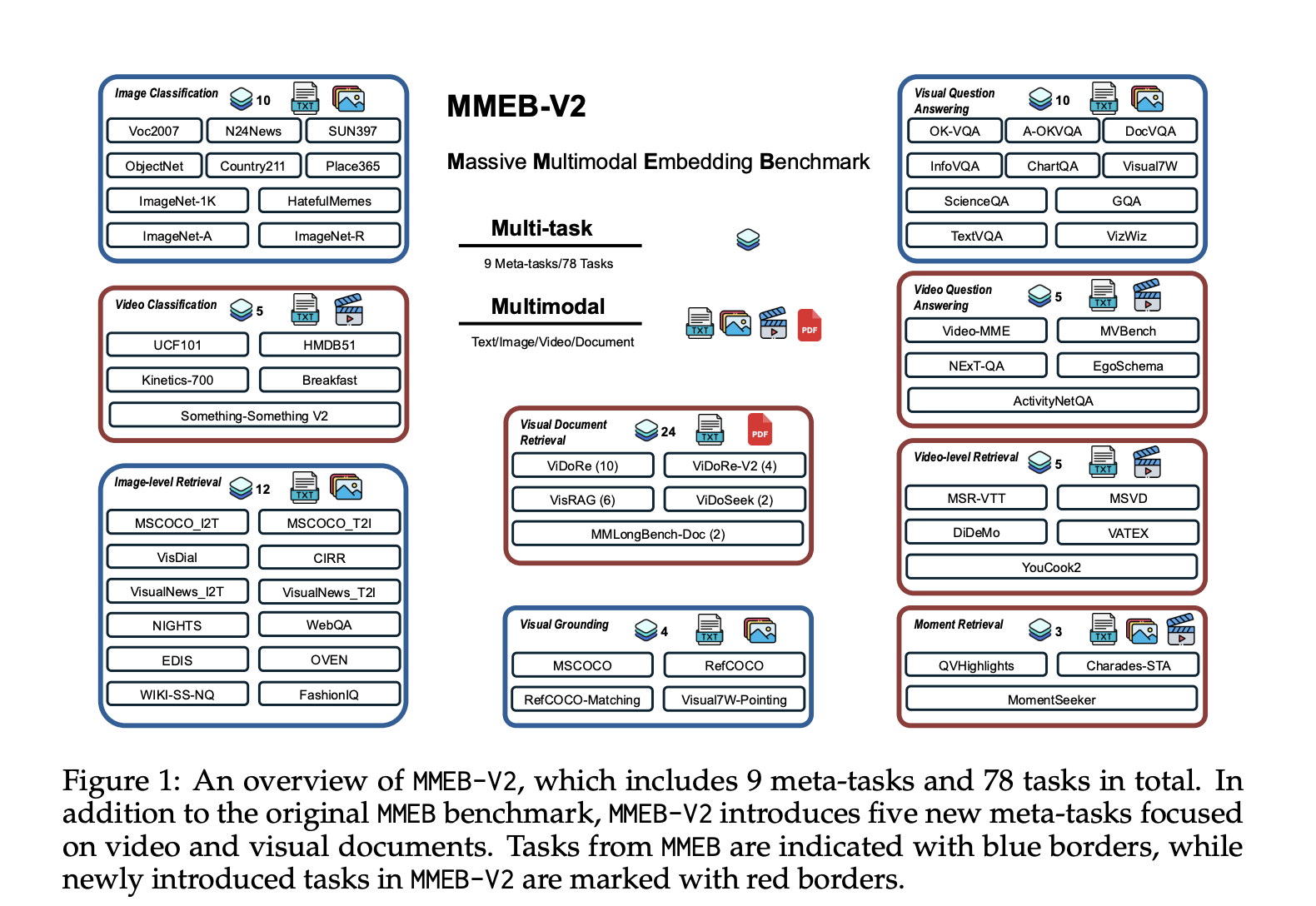
Recent progress in large foundation models has accelerated the development of embedding models. However, existing multimodal solutions have been largely limited to traditional datasets such as MMEB and M-BEIR, which predominantly focus on natural images and photographs sourced from MSCOCO, Flickr, and ImageNet. Unfortunately, these datasets do not encompass the broader spectrum of visual information, including documents, PDFs, websites, videos, and presentation slides.
Challenges with Current Models
This narrow focus has resulted in significant limitations for embedding models, particularly when applied to more realistic tasks such as article searching, website navigation, and YouTube video discovery. The performance of these models in practical applications has been less than optimal due to the lack of diverse training data.
Advancements in Multimodal Embedding
Historically, multimodal embedding benchmarks like MSCOCO, Flickr30K, and Conceptual Captions have concentrated on static image-text pairs, primarily for image captioning and retrieval tasks. In contrast, more recent benchmarks, including M-BEIR and MMEB, have introduced multi-task evaluations to advance the capabilities of these embedding models.
VLM2Vec-V2 aims to expand on these foundations by incorporating a wider variety of visual content. This holistic approach not only enhances the model's ability to process and understand complex visual information but also significantly improves its utility in real-world applications.
As the field of artificial intelligence continues to evolve, VLM2Vec-V2 represents a promising step forward in the creation of more robust and versatile embedding models, paving the way for enhanced interactions with diverse forms of multimedia.
Rocket Commentary
The introduction of VLM2Vec-V2 is a noteworthy step in the evolution of multimodal embedding learning, showcasing the industry's commitment to integrating diverse data types into a cohesive framework. However, the reliance on traditional datasets such as MMEB and M-BEIR highlights a critical gap in truly representing the vast array of visual information available today. For AI to be accessible and transformative, it is essential that future developments expand beyond conventional images and encompass formats like documents and videos. This broadening of scope will enable more ethical and practical applications of AI in business, allowing for richer insights and innovative solutions that reflect the complexity of real-world data. The industry must seize this opportunity to ensure that advancements in AI not only enhance capabilities but also democratize access to diverse information, fostering a more inclusive technological landscape.
Read the Original Article
This summary was created from the original article. Click below to read the full story from the source.
Read Original Article