Introducing REST: A New Framework for Evaluating Large Reasoning Models
Large Reasoning Models (LRMs) have made significant strides in recent years, demonstrating exceptional capabilities in tackling complex problem-solving tasks across various fields such as mathematics, coding, and scientific reasoning. Nonetheless, traditional evaluation methods predominantly focus on single-question assessments, unveiling critical limitations in their effectiveness.
The Need for a Comprehensive Evaluation Framework
Current benchmarks, like GSM8K and MATH, primarily assess LRMs by presenting them with one question at a time. While this approach has been useful for initial model development, it presents two major drawbacks:
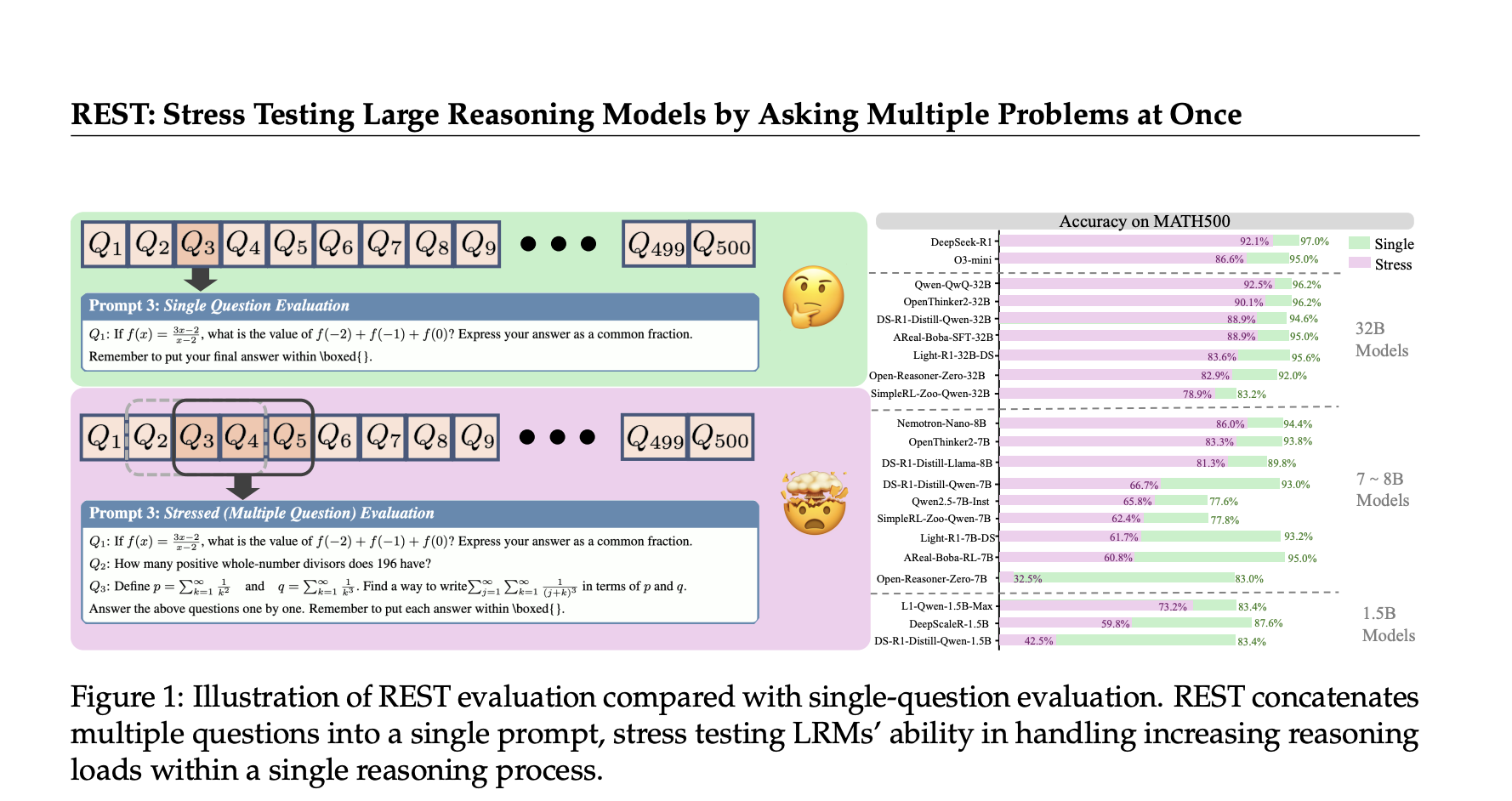
- Decreasing Discriminative Power: Many leading LRMs have achieved nearly perfect scores on existing benchmarks. For instance, the DeepSeek-R1 model boasts a 97% accuracy rate on MATH500. These high scores complicate the task of identifying genuine improvements in model capabilities, necessitating the continuous development of increasingly challenging datasets.
- Lack of Real-World Multi-Context Evaluation: Most real-world applications, such as educational tutoring and multitasking AI assistants, demand an ability to reason across multiple contexts simultaneously. The existing single-question testing framework fails to reflect these complex requirements.
To address these challenges, REST (Reasoning Evaluation through Simultaneous Testing) has been introduced. This innovative multi-problem stress-testing framework aims to extend the evaluation of LRMs beyond isolated problem-solving scenarios. By doing so, it seeks to provide a more accurate representation of their reasoning capabilities in real-world applications.
The Future of Evaluation in AI
As the field of artificial intelligence continues to evolve, the introduction of frameworks such as REST could significantly enhance how we assess the capabilities of LRMs. This advancement not only promises to refine the evaluation process but also to ensure that these models are truly equipped to handle the complexities of real-life tasks.
Rocket Commentary
The article highlights a critical juncture for Large Reasoning Models (LRMs) as they achieve impressive benchmark scores, revealing a pressing need for a more nuanced evaluation framework. The current reliance on single-question assessments, while foundational, fails to capture the multifaceted capabilities of these models, potentially stifling innovation. As LRMs become integral to sectors like mathematics and coding, the industry must pivot toward comprehensive evaluations that reflect real-world applications and challenges. This shift will not only enhance model development but also ensure that AI remains accessible and ethical, fostering transformative solutions that address complex problems in business and society. Embracing this opportunity can lead to more robust, reliable AI systems, ultimately benefiting users and developers alike.
Read the Original Article
This summary was created from the original article. Click below to read the full story from the source.
Read Original Article