Introducing FEEDER: A New Framework for Efficient Demonstration Selection in LLMs
Recent advancements in large language models (LLMs) have showcased their exceptional performance across various tasks, largely attributed to few-shot inference, commonly known as in-context learning (ICL). However, a significant challenge persists in the selection of the most representative demonstrations from vast training datasets.
Challenges in Demonstration Selection
Traditionally, early methods have relied on similarity scores to select demonstrations based on their relevance to an input question. While effective, these approaches often struggle as the number of examples increases, leading to substantial computational overhead. Current methodologies have introduced additional selection rules to improve the efficiency of this process, but they also contribute to increased complexity.
The FEEDER Solution
In response to these challenges, researchers from Shanghai Jiao Tong University, Xiaohongshu Inc., Carnegie Mellon University, Peking University, University College London, and the University of Bristol have proposed a novel pre-selection framework named FEEDER (FEw yet Essential Demonstration prE-selectoR). This innovative method aims to streamline the identification of a core subset of demonstrations, ensuring that only the most representative examples are utilized in training.
Key Features of FEEDER
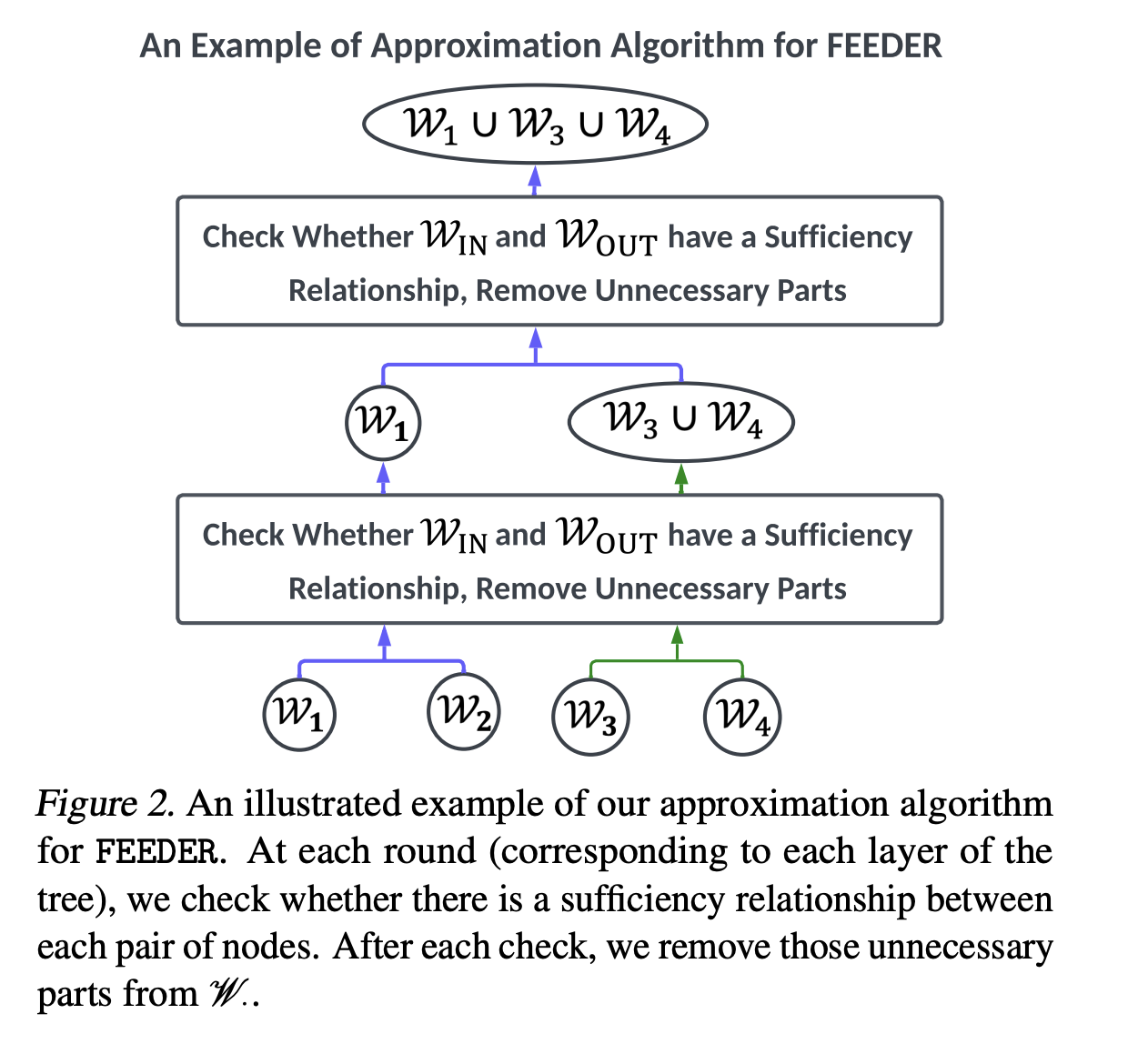
- Metrics for Selection: FEEDER employs “sufficiency” and “necessity” metrics during the pre-selection stage, which are designed to optimize the relevance of selected demonstrations.
- Algorithm Efficiency: A tree-based algorithm is utilized to efficiently manage the selection process, thereby reducing computational demands.
- Data Reduction: The framework has been shown to decrease the required training data size by 20% while maintaining performance levels, a significant improvement for practitioners in the field.
Implications for LLMs
It is crucial for the effectiveness of selected demonstrations to align with the specific capabilities and knowledge domains of different LLMs. By tailoring the demonstration selection process, FEEDER offers a more efficient pathway for training LLMs, ultimately enhancing their performance across a variety of applications.
As the field of artificial intelligence continues to evolve, the introduction of frameworks like FEEDER marks a pivotal step towards enhancing the efficiency and effectiveness of LLM training processes.
Rocket Commentary
The article highlights the remarkable capabilities of large language models (LLMs) and their reliance on in-context learning, yet it underscores a critical bottleneck: the challenge of demonstration selection. While existing methods use similarity scores, their inefficiency escalates with larger datasets, raising concerns about scalability in practical applications. As we strive for AI that is accessible, ethical, and transformative, the industry must prioritize refining these selection processes. Streamlining demonstration selection will not only enhance performance but also reduce computational costs, making advanced AI technologies more viable for businesses and developers. This is an opportunity for innovation that can democratize access to LLMs, fostering an environment where AI can truly serve diverse industries efficiently.
Read the Original Article
This summary was created from the original article. Click below to read the full story from the source.
Read Original Article