Google AI Revolutionizes LLM Training with Dramatic Data Reduction
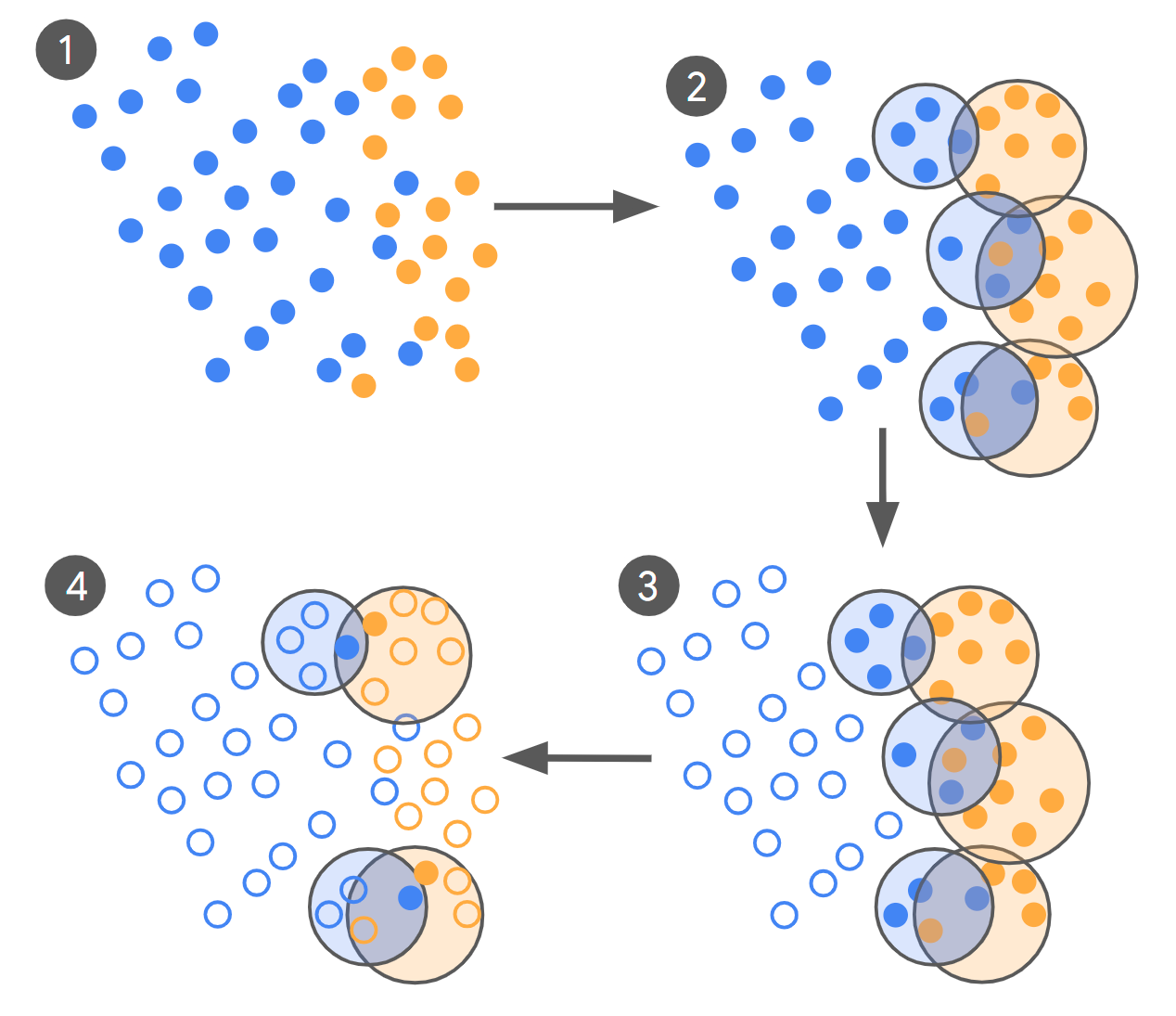
Google Research has introduced a revolutionary approach to fine-tuning large language models (LLMs) that significantly reduces the amount of training data required, cutting it down by as much as 10,000 times while preserving or enhancing model quality. This innovative method focuses on active learning, concentrating expert labeling efforts on the most informative examples, particularly the so-called “boundary cases” where model uncertainty is highest.
The Traditional Bottleneck
Traditionally, fine-tuning LLMs for tasks that demand intricate contextual and cultural understanding—such as content safety in advertisements or moderation—has relied on extensive, high-quality labeled datasets. However, much of the data is benign, meaning that only a small fraction of examples are crucial for detecting policy violations. This reality escalates the cost and complexity of data curation. Additionally, standard methods often falter when policies or patterns shift, leading to expensive retraining processes.
Google’s Active Learning Breakthrough
Google's new approach leverages the capabilities of LLMs to act as scouts. This involves scanning vast corpora to identify boundary cases that are most likely to influence model performance. By focusing on these critical examples, the need for large datasets is dramatically reduced.
Benefits of the New Method
- Cost Efficiency: Reducing the amount of data needed lowers data curation expenses.
- Enhanced Model Quality: Focusing on boundary cases improves the overall performance of the models.
- Agility in Adaptation: The method allows for quicker adjustments to policy shifts without extensive retraining.
This breakthrough in active learning signifies a major leap forward in the field of artificial intelligence, particularly in the development and deployment of LLMs. As the landscape of AI continues to evolve, methods like these could redefine how organizations approach data training and model implementation.
According to reports from Google Research, this technique not only mitigates the traditional bottlenecks associated with LLM training but also sets a precedent for future innovations in artificial intelligence.
Rocket Commentary
The introduction of Google's fine-tuning approach for large language models represents a significant leap forward in AI development, particularly in how we can harness data more efficiently. By concentrating on active learning and identifying boundary cases, this method not only minimizes the resources needed for training but also enhances model reliability in critical applications like content moderation. However, while the reduction of training data by such a staggering factor is commendable, we must remain vigilant about the ethical implications of this shift. As AI becomes more capable yet less data-dependent, ensuring that the models are trained on diverse and representative datasets is crucial to avoid inherent biases. This innovation has the potential to democratize AI, making advanced tools accessible to smaller businesses that previously could not afford the extensive data curation efforts. Ultimately, this could transform industries, but the emphasis must remain on responsible deployment to ensure that the benefits are equitably shared.
Read the Original Article
This summary was created from the original article. Click below to read the full story from the source.
Read Original Article