Accenture Research Unveils MCP-Bench: A Groundbreaking Benchmark for LLM Agents
In a significant advancement for artificial intelligence (AI), Accenture Research has introduced MCP-Bench, a large-scale benchmark designed to evaluate large language models (LLMs) in complex real-world tasks. This innovative tool aims to address the limitations of existing benchmarks that have not adequately tested the capabilities of LLMs in practical applications.
The Need for Effective Benchmarking
Modern LLMs have evolved far beyond mere text generation. Today’s most promising applications require these models to leverage external tools such as APIs, databases, and software libraries to tackle intricate tasks. However, a critical question arises: how can we determine if an AI agent can effectively plan, reason, and coordinate with these tools in a manner similar to a human assistant?
Current benchmarks often fall short, focusing primarily on one-off API calls or narrowly defined workflows. Even advanced evaluations rarely assess an agent's ability to discover and effectively chain the appropriate tools from ambiguous real-world instructions. As a result, many LLMs perform admirably on artificial tasks but struggle in the face of real-world complexity and ambiguity.
Introducing MCP-Bench
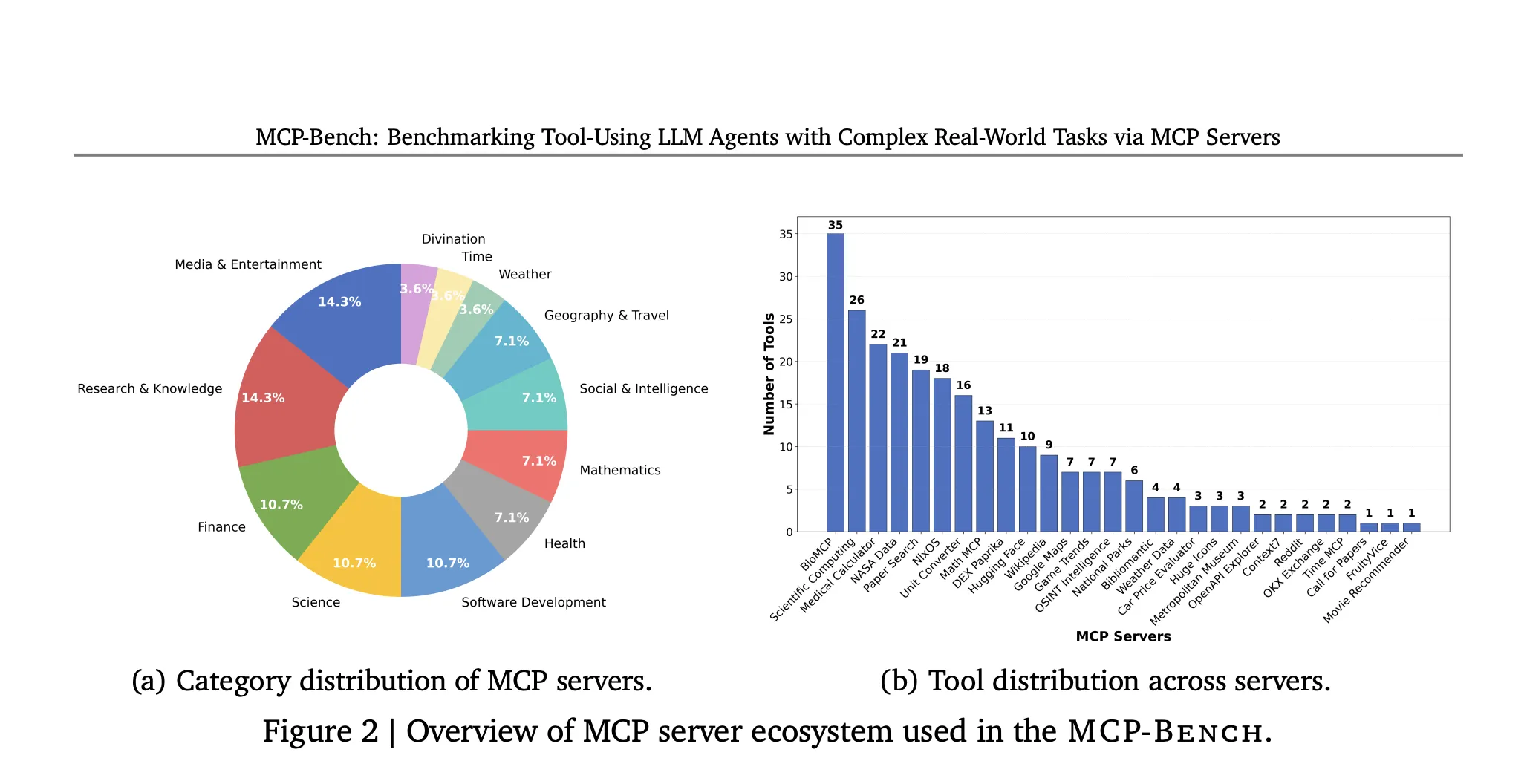
To bridge this gap, the MCP-Bench initiative connects LLM agents to 28 real-world servers that provide a diverse array of tools across various domains, including finance, scientific computing, healthcare, travel, and academia. This Model Context Protocol (MCP)-based benchmark enables more comprehensive evaluations by simulating the conditions under which LLMs must operate in real-world scenarios.
According to the researchers at Accenture, this new benchmark will facilitate a deeper understanding of how well LLMs can navigate complex tasks that require multi-domain coordination and evidence-based grounding of their outputs. The MCP-Bench is expected to become a vital resource for developers and researchers aiming to enhance the capabilities of AI agents.
Conclusion
The introduction of MCP-Bench marks a pivotal moment in the ongoing evolution of large language models. By providing a more robust framework for evaluation, Accenture Research is poised to drive significant advancements in the development and application of AI technologies.
Rocket Commentary
Accenture Research's introduction of MCP-Bench marks a pivotal step in how we assess large language models, moving beyond superficial text generation to evaluating their practical, real-world applications. This shift is essential, as it addresses a significant gap in current benchmarks that fail to measure an AI's ability to integrate and coordinate with external tools. As AI continues to evolve, the need for rigorous, contextually relevant evaluation methods becomes paramount. MCP-Bench not only provides a framework for assessing AI capabilities but also underscores the importance of making AI accessible and ethical in its applications. By ensuring that these models can perform complex tasks akin to human assistants, we open doors to transformative opportunities across industries, enhancing productivity and innovation while prioritizing responsible deployment.
Read the Original Article
This summary was created from the original article. Click below to read the full story from the source.
Read Original Article